实用工具目录
- 一、日志分析
- 使用方法
- 实际案例
- 二、结果分析
- pkl结果文件生成
- 使用方法
- 实际案例
- 三、混淆矩阵
- 使用方法
- 实际案例
- 遇到的UserWarning
- 解决方案
MMDetection官方除了训练和测试脚本,他们还在 mmdetection/tools/ 目录下提供了许多有用的工具。本帖先为大家重点介绍其中三个简单而实用的工具:日志分析、结果分析、混淆矩阵。
一、日志分析
tools/analysis_tools/analyze_logs.py 可利用指定的训练 log 文件绘制 loss/mAP 曲线图, 第一次运行前请先运行 pip install seaborn 安装必要依赖。
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
使用方法
以下是官方模板(记得勾选 paste as one line)
python tools/analysis_tools/analyze_logs.py plot_curve
[--keys ${KEYS}] [--eval-interval ${EVALUATION_INTERVAL}]
[--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}]
[--style ${STYLE}] [--out ${OUT_FILE}]
-
绘制分类损失曲线图
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls -
绘制分类损失、回归损失曲线图,保存图片为对应的 pdf 文件
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf -
在相同图像中比较两次运行结果的 bbox mAP
python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2 -
计算平均训练速度
python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
实际案例
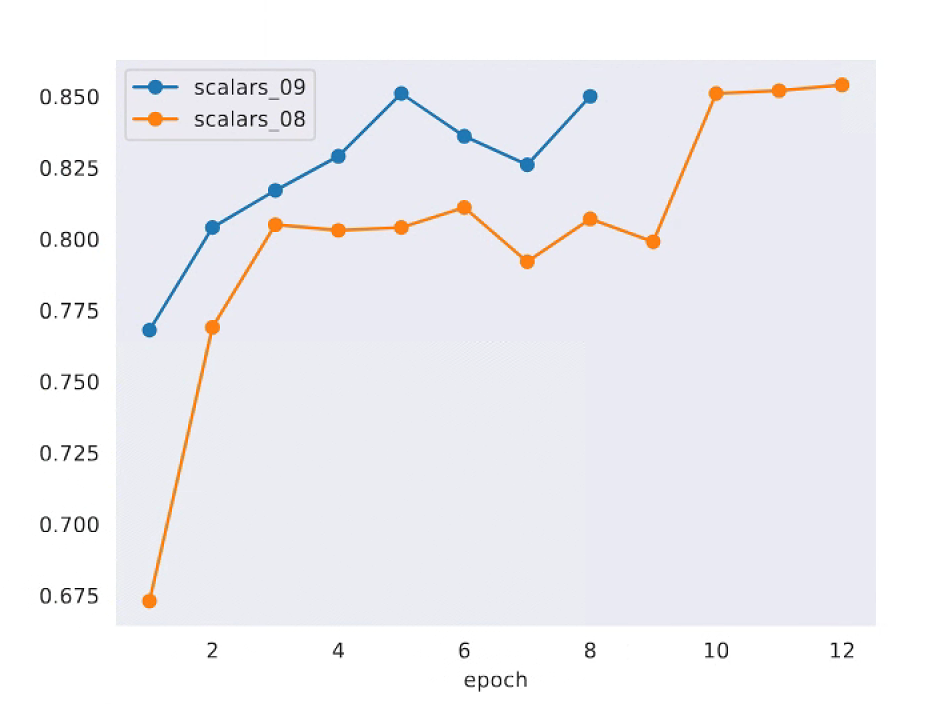
在自己模型训练日志保存的mmdetection/work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford文件夹下找到不同训练策略下产生的.json文件,比较两次训练结果的bbox mAP。
python tools/analysis_tools/analyze_logs.py plot_curve
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/20240509_175112/vis_data/scalars.json
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/20240508_120431/vis_data/scalars.json
--keys bbox_mAP
--legend scalars_09 scalars_08
--out mAP/scalars_mAP.pdf
之后在mAP的文件夹将会生成一个以epoch为横轴的bbox mAP精度分析折线图,其中黄线代表正常训练策略下bbox的精度走势,蓝线代表微调策略下bbox的精度走势。
二、结果分析
pkl结果文件生成
利用配置文件和模型训练权重文件在tools/test.py指定生成pickle结果文件
python tools/test.py \
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/faster-rcnn_r50_fpn_ms-3x_coco_oxford.py \
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/iter_7080.pth \
--out results.pkl \
--show
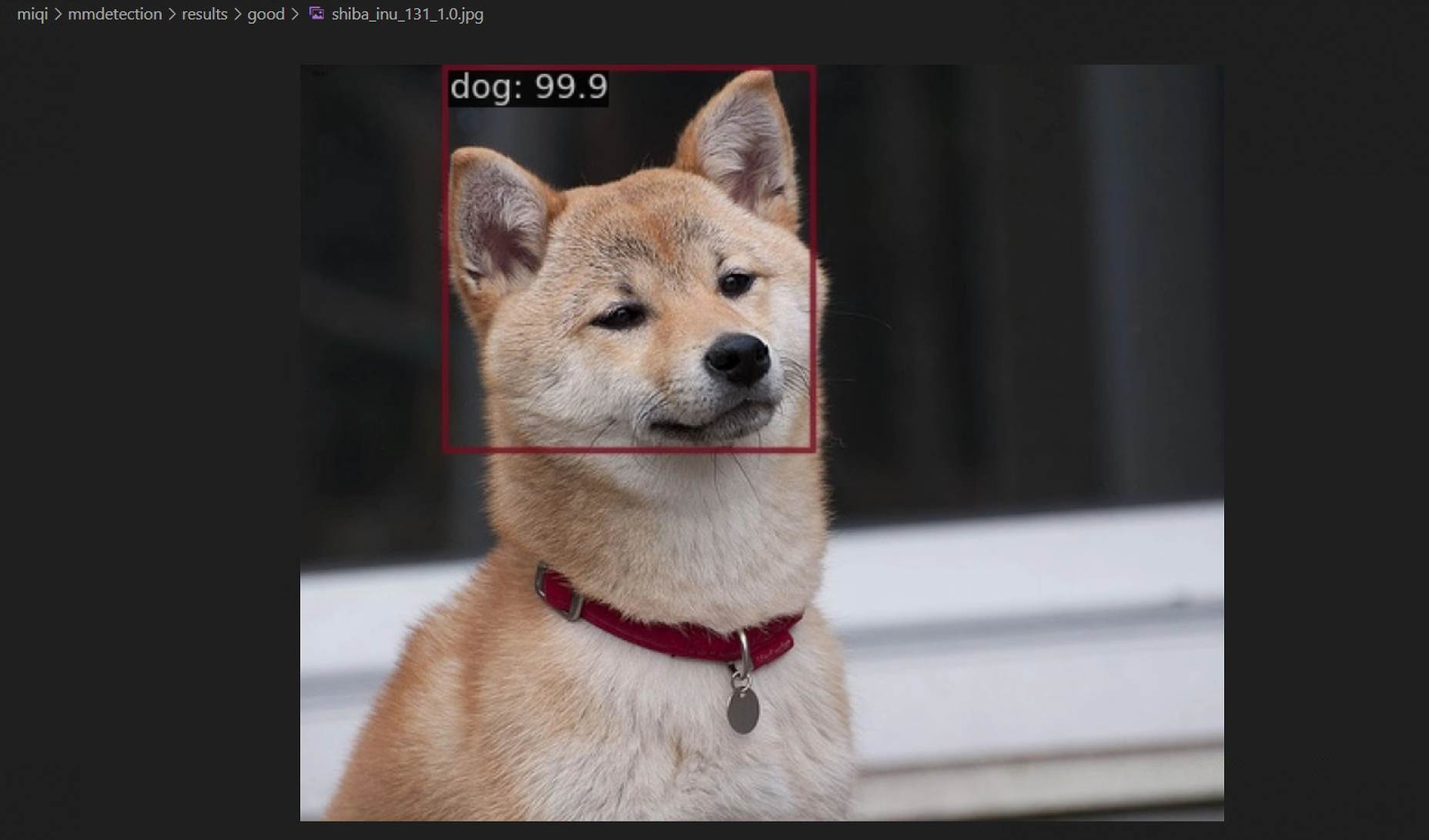
使用 tools/analysis_tools/analyze_results.py 可计算每个图像 mAP,随后根据真实标注框与预测框的比较结果,展示或保存最高与最低 top-k 得分的预测图像。
使用方法
python tools/analysis_tools/analyze_results.py \
${CONFIG} \
${PREDICTION_PATH} \
${SHOW_DIR} \
[--show] \
[--wait-time ${WAIT_TIME}] \
[--topk ${TOPK}] \
[--show-score-thr ${SHOW_SCORE_THR}] \
[--cfg-options ${CFG_OPTIONS}]
各个参数选项的作用:
config: model config 文件的路径。prediction_path: 使用tools/test.py输出的 pickle 格式结果文件。show_dir: 绘制真实标注框与预测框的图像存放目录。--show:决定是否展示绘制 box 后的图片,默认值为False。--wait-time: show 时间的间隔,若为 0 表示持续显示。--topk: 根据最高或最低topk概率排序保存的图片数量,若不指定,默认设置为20。--show-score-thr: 能够展示的概率阈值,默认为0。--cfg-options: 如果指定,可根据指定键值对覆盖更新配置文件的对应选项
Top-K准确率(Top-K Accuracy)是一个相关的评价指标,它衡量的是模型预测的最高K个类别中是否包含了真实类别。如果真实类别位于模型预测概率最高的K个类别之中,则这次预测被认为是正确的,即便它不是概率最高的那个类别。这种评估方式在实践中特别有用,因为它能够反映出模型在面对多个可能正确答案时的鲁棒性,特别是在类别间区分度较低的情况下。
实际案例
在mmdetection文件夹下新建results文件夹,再选用额外需要的可选参数
CUDA_VISIBLE_DEVICES=1 \
python tools/analysis_tools/analyze_results.py \
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/faster-rcnn_r50_fpn_ms-3x_coco_oxford.py \
results.pkl \
results \
--topk 50
最后会生成mmdetection/results/bad和mmdetection/results/good文件夹
三、混淆矩阵
混淆矩阵(Confusion Matrix)是对检测结果的概览,是一种用于评估和可视化分类模型性能的重要工具。它以表格形式展现,直观地显示了模型预测类别与实际类别之间的对应关系,特别是对于错分情况的细节。
使用方法
首先,运行 tools/test.py 保存 .pkl 预测结果。 之后再运行
python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
根据配置文件和pickle结果文件生成如下图所示的混淆矩阵

实际案例
python tools/analysis_tools/confusion_matrix.py
work_dirs/faster-rcnn_r50_fpn_ms-3x_coco_oxford/faster-rcnn_r50_fpn_ms-3x_coco_oxford.py
results.pkl
results/confusion_matrix
--show
遇到的UserWarning

报错
UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations. fig.tight_layout()
查看生成的图片发现的确发现混淆矩阵的横纵坐标有被遮挡导致显示不完全

解决方案
在mmdetection/tools/analysis_tools/confusion_matrix.py下修改源码
VSCode环境下快捷键
Ctrl+F进入查找界面搜索subplots快速对应
fig, ax = plt.subplots(
figsize=(0.7 * num_classes, 0.7 * num_classes * 0.7), dpi=180)
上述情况经反复校验,我将0.7全部换成1.5之后,即可生成完整的混淆矩阵图片